ubuntu配置hadoop-Ubuntu配置Hadoop:挑战与细节揭秘
创始人
2024-12-14 09:18:49
0次
Ubuntu下配置Hadoop是一项复杂而又有挑战的任务。作为一名资深的数据工程师,我深知这个过程中的种种细节和困难。首先,我们需要明确Ubuntu是一个开源的操作系统,而Hadoop则是一个用于分布式存储和处理大规模数据的开源软件框架。将它们结合起来,可以为数据处理提供强大的支持。

在配置Hadoop之前,首先要确保系统环境的准备工作。这包括安装Java环境、设置SSH免密登录、配置系统变量等。这些步骤看似简单,但却是搭建Hadoop环境的基础,任何一步出错都可能导致后续的问题。

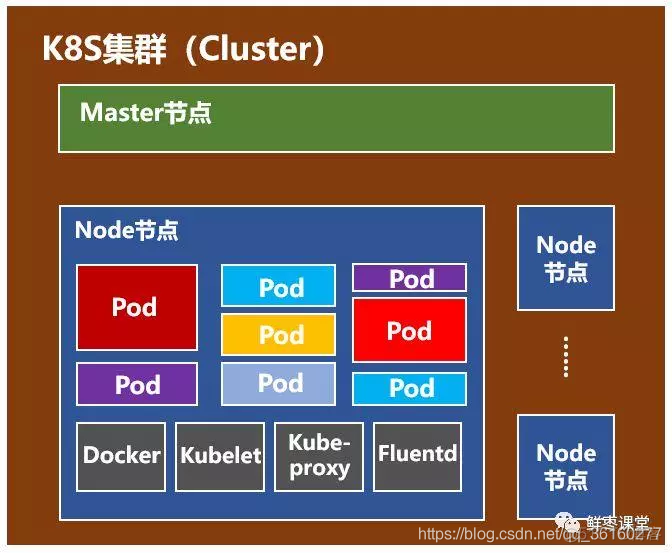
接下来,我们需要下载并解压Hadoop的安装包,配置Hadoop的环境变量,以及修改Hadoop的配置文件。这些步骤需要耐心和细心,因为配置文件的修改直接影响到Hadoop集群的运行。在配置文件中,我们需要指定各个节点的角色和配置信息,包括NameNode、DataNode、ResourceManager、NodeManager等。
配置完环境变量和配置文件后,我们需要启动Hadoop集群,并进行一系列的测试。
tokenpocket官网版下载:https://cjge-manuscriptcentral.com/software/65916.html
相关内容
热门资讯
安卓系统安装不了instagr...
安卓系统无法安装Instagram的常见原因及解决方案随着社交媒体的普及,Instagram已成为全...
希沃安卓系统重置,轻松恢复设备...
亲爱的读者们,你是否也和我一样,对希沃智能平板的安卓系统重置充满了好奇呢?想象你的平板突然卡住了,屏...
vivo手机系统和安卓系统吗,...
你有没有想过,你的vivo手机里那个神秘的操作系统,它到底是不是安卓系统呢?别急,让我来给你揭秘这个...
鸿蒙降级安卓10系统,操作指南...
你有没有想过,你的手机系统也能来个华丽丽的变身?没错,就是那个最近风头无两的鸿蒙系统。不过,你知道吗...
安卓系统咋设置录音,轻松开启录...
你有没有想过,有时候想要记录下生活中的点点滴滴,却发现手机录音功能设置得有点复杂?别急,今天就来手把...
安卓系统激活苹果手表,跨平台使...
你有没有想过,即使你的手机是安卓的,也能让那炫酷的苹果手表在你的手腕上翩翩起舞呢?没错,就是那个一直...
呼叫转移安卓系统,设置、操作与...
手机里总有一些时候,你不想接电话,但又不想错过重要的来电。这时候,呼叫转移功能就派上大用场啦!今天,...
安卓系统怎么不能youtube...
你的安卓系统为何无法访问YouTube?在数字化时代,YouTube已成为全球数十亿用户的热门视频网...
windows操作系统文件后缀...
Windows操作系统文件后缀显示状态详解在Windows操作系统中,文件后缀名是标识文件类型的重要...
安卓系统怎么设置呼叫,呼叫设置...
手机响了!是不是又有人找你啦?别急,别急,今天就来教你怎么在安卓手机上设置呼叫转移,让你的电话生活更...