python如何加载pickle模块, 引言
Pyho中pickle模块的加载与使用详解
引言
pickle模块是Pyho标准库中的一个重要组成部分,它提供了对象的序列化和反序列化功能。序列化是指将Pyho对象转换为字节流的过程,而反序列化则是将字节流恢复为原始对象的过程。通过pickle模块,我们可以轻松地将对象保存到文件中,也可以从文件中读取对象。本文将详细介绍如何在Pyho中加载和使用pickle模块。
1. 简介

pickle模块是Pyho标准库的一部分,因此无需额外安装。在Pyho代码中,你可以通过以下方式导入pickle模块:
```pyho
impor pickle
2. 使用pickle.dump()进行序列化
```pyho
impor pickle
daa = {'ame': 'Alice', 'age': 30, 'ciy': 'ew York'}
wih ope('daa.pkl', 'wb') as file:
pickle.dump(daa, file)
在这个例子中,我们创建了一个包含名字、年龄和城市的字典对象,并将其序列化保存到名为`daa.pkl`的文件中。
3. 使用pickle.load()进行反序列化

```pyho
impor pickle
wih ope('daa.pkl', 'rb') as file:
loaded_daa = pickle.load(file)
pri(loaded_daa)
在这个例子中,我们从`daa.pkl`文件中读取了之前保存的字典对象,并打印出来。
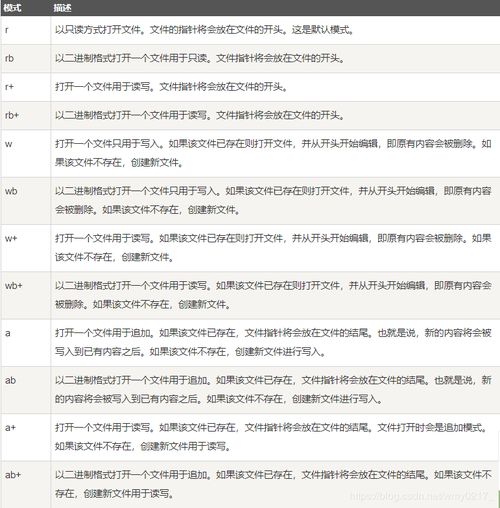
1. 文件模式
在使用`pickle.dump()`和`pickle.load()`时,需要注意文件模式。对于序列化,应该使用二进制写模式(`'wb'`),而对于反序列化,应该使用二进制读模式(`'rb'`)。这是因为pickle序列化的数据是二进制的,而不是文本格式。
2. 安全性
3. pickle版本兼容性

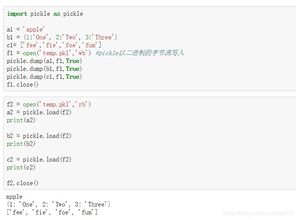
1. 使用pickle.dumps()和pickle.loads()
除了直接使用`pickle.dump()`和`pickle.load()`,还可以使用`pickle.dumps()`和`pickle.loads()`函数。`pickle.dumps()`用于序列化对象,返回一个字节串,而`pickle.loads()`用于反序列化字节串。
```pyho
impor pickle
daa = {'ame': 'Alice', 'age': 30, 'ciy': 'ew York'}
serialized_daa = pickle.dumps(daa)
loaded_daa = pickle.loads(serialized_daa)
2. 保存和加载特定对象
除了保存和加载整个对象,pickle还可以用于保存和加载对象的特定部分。例如,你可以使用`pickle.dump()`和`pickle.load()`来保存和加载对象的属性。
```pyho
impor pickle
class Perso:
def __ii__(self, ame, age, ciy):
self.ame = ame
self.age = age
self.ciy = ciy
perso = Perso('Alice', 30, 'ew York')
wih ope('perso.pkl', 'wb') as file:
pickle.dump(perso.ame, file)
pickle.dump(perso.age, file)
pickle.dump(perso.ciy, file)
wih ope('perso.pkl', 'rb') as file:
perso.ame = pickle.load(file)
perso.age = pickle.load(file)
perso.ciy = pickle.load(file)